Modelltypen in der Informatik
Sechs zentrale Modelltypen — klicke eine Karte an, um Abstraktionsgrad, Darstellungsart, Zielorientierung und Einsatzbereich zu sehen.
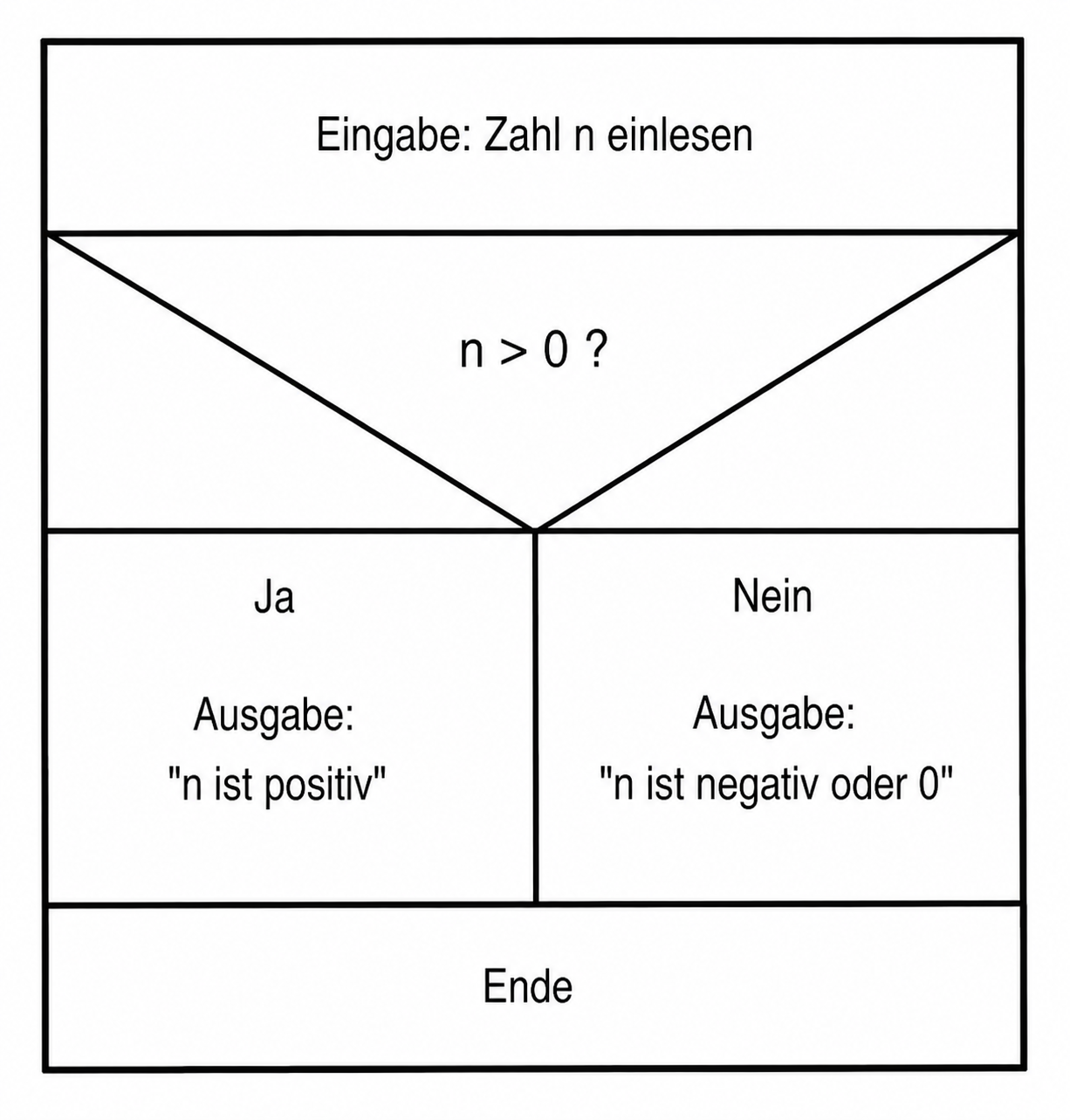
Einsatz: Algorithmen entwerfen und dokumentieren, bevor Code geschrieben wird. Besonders bei Schleifen und Verzweigungen übersichtlich.
Stärke: Zeigt Struktur eindeutig, keine Sprünge möglich (kein goto). Gut für Unterricht.
Schwäche: Bei sehr langen Algorithmen unübersichtlich.
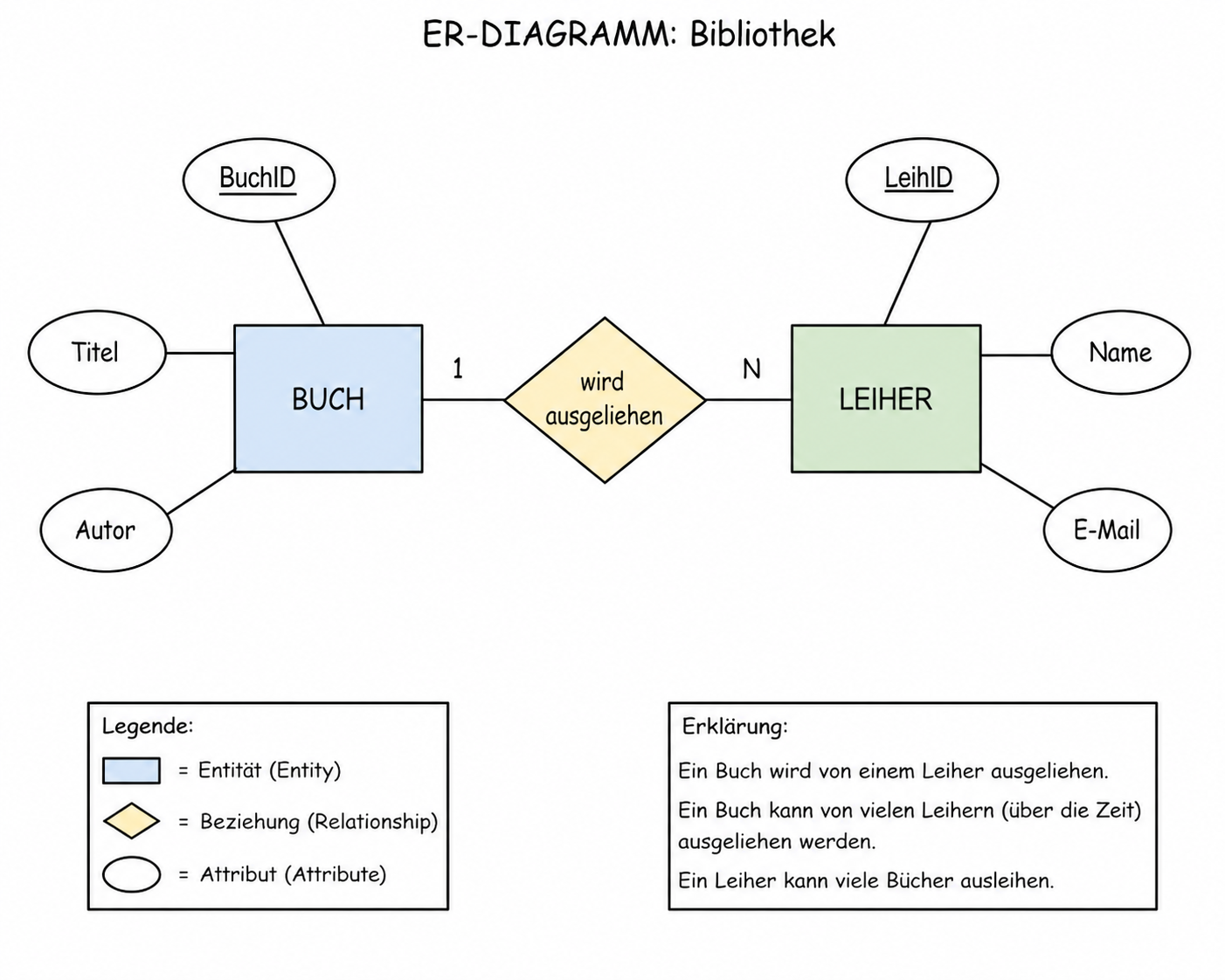
Einsatz: Datenbankdesign — bevor Tabellen erstellt werden. Kommunikation zwischen Entwicklern und Kunden.
Stärke: Sprachunabhängig, intuitiv verständlich, zeigt Beziehungen (1:1, 1:n, m:n) klar.
Schwäche: Zeigt keine Algorithmen oder Abläufe.
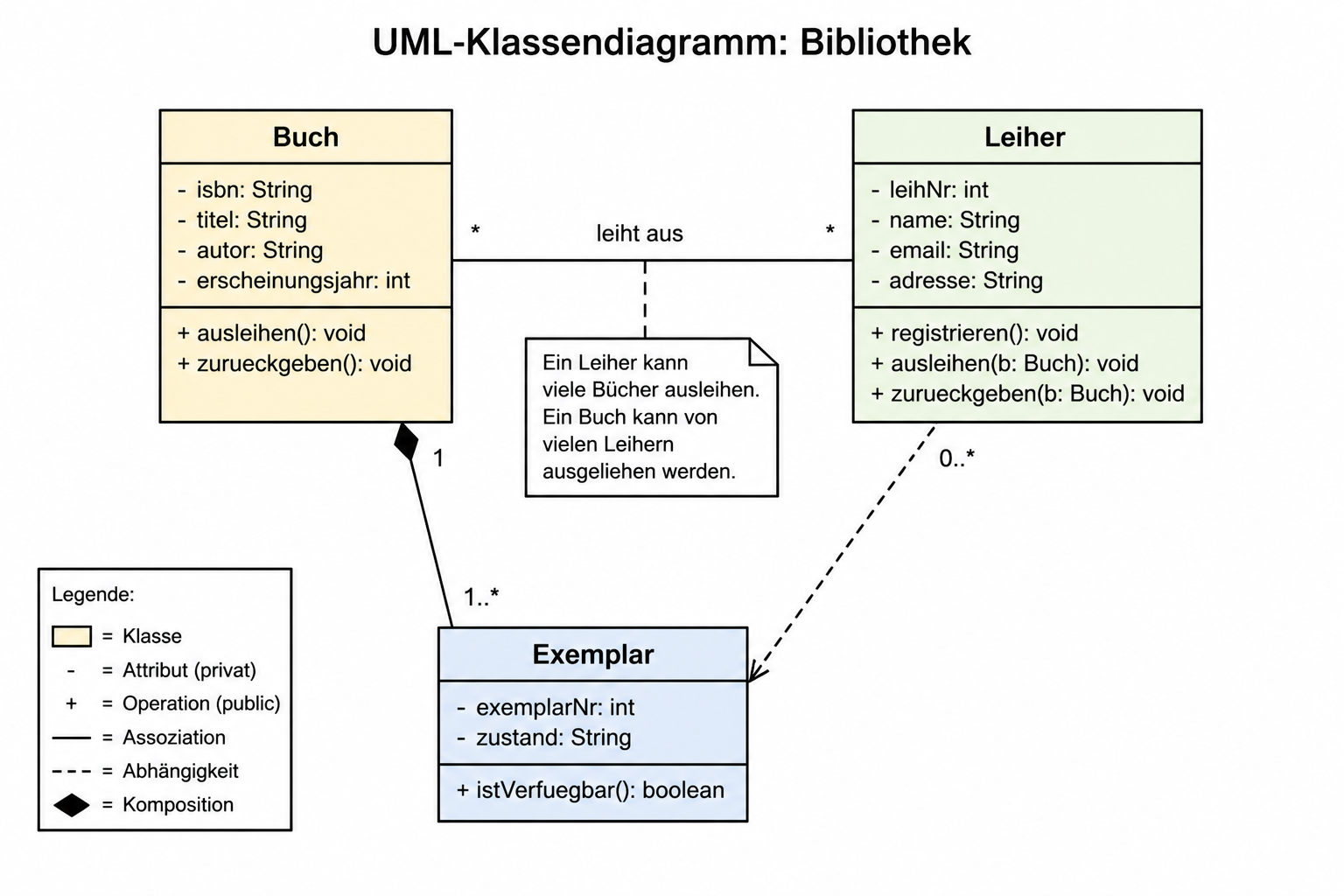
Einsatz: Softwarearchitektur planen. Vererbung, Assoziation, Aggregation, Komposition darstellen.
Stärke: Industriestandard, werkzeugunterstützt, kann in Code umgewandelt werden.
Schwäche: Viele Notationsvarianten, Lernkurve.
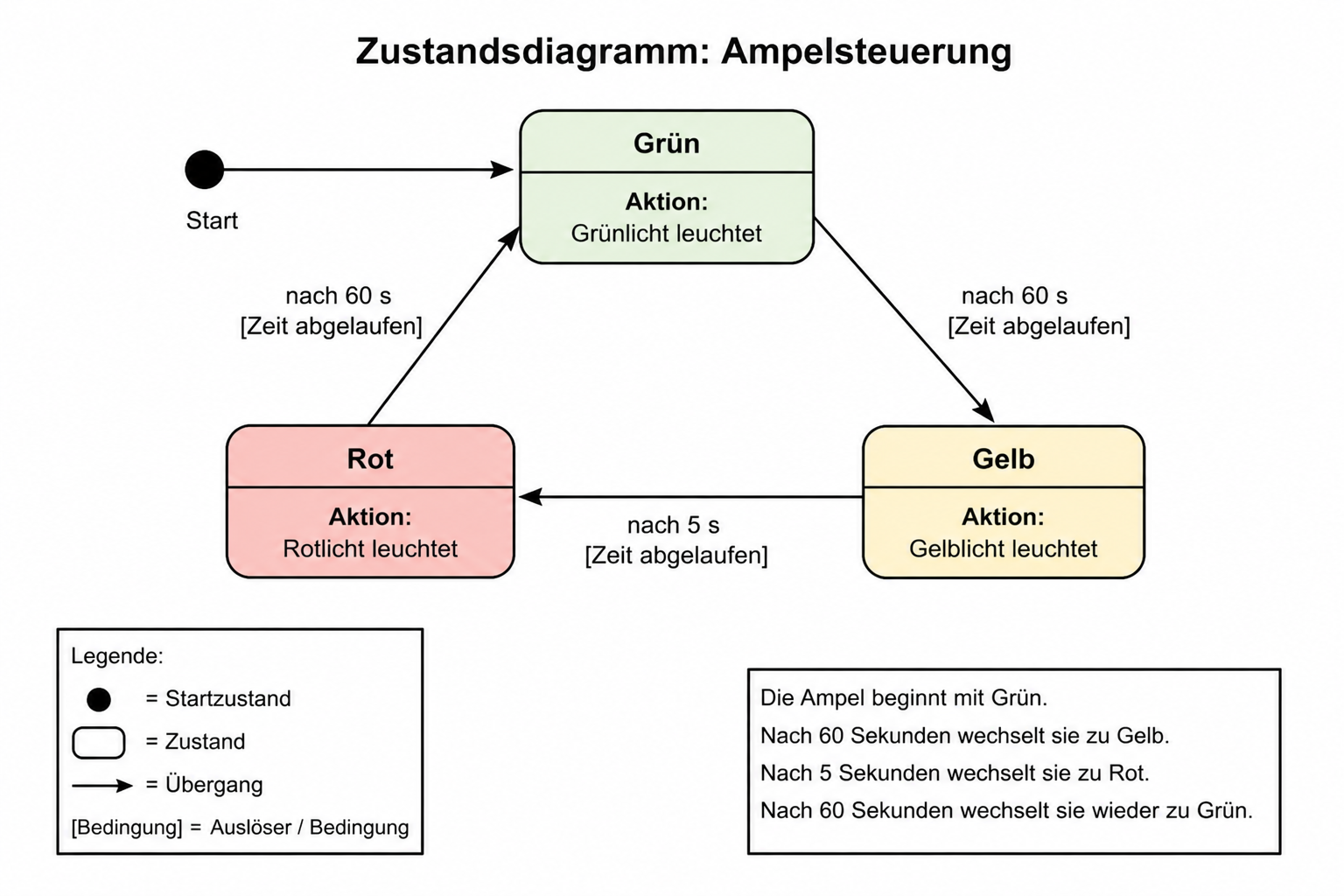
Einsatz: Reaktive Systeme modellieren: Ampelsteuerung, Benutzeroberflächen, Protokolle, Bestellprozesse.
Stärke: Zeigt dynamisches Verhalten, alle möglichen Zustände und Übergänge auf einen Blick.
Schwäche: Bei vielen Zuständen unübersichtlich (State-Explosion).
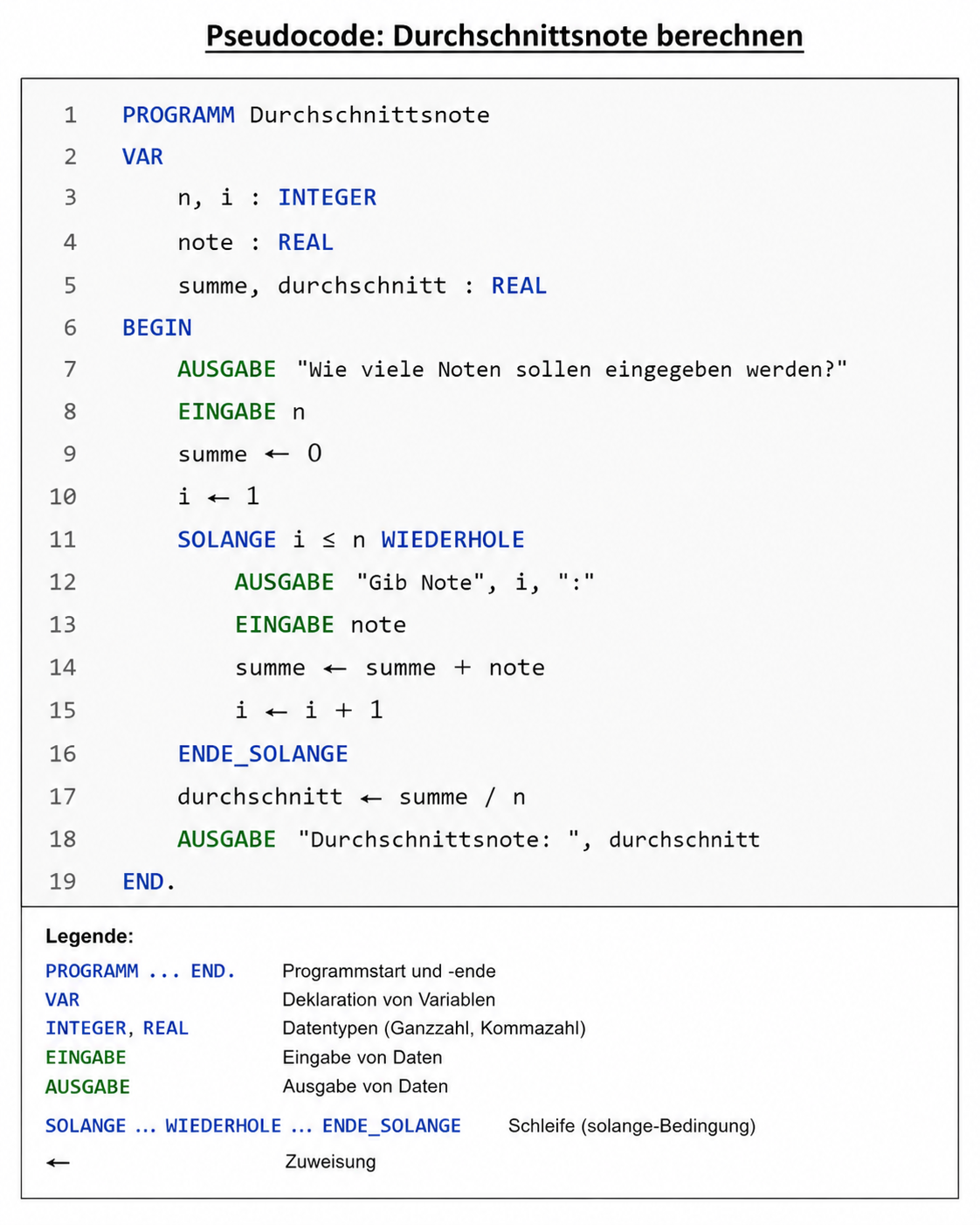
Einsatz: Algorithmen beschreiben, bevor sie in einer Programmiersprache implementiert werden. Sprachübergreifende Kommunikation.
Stärke: Flexibel, leicht lesbar, keine spezielle Software nötig.
Schwäche: Kein einheitlicher Standard, nicht direkt ausführbar.
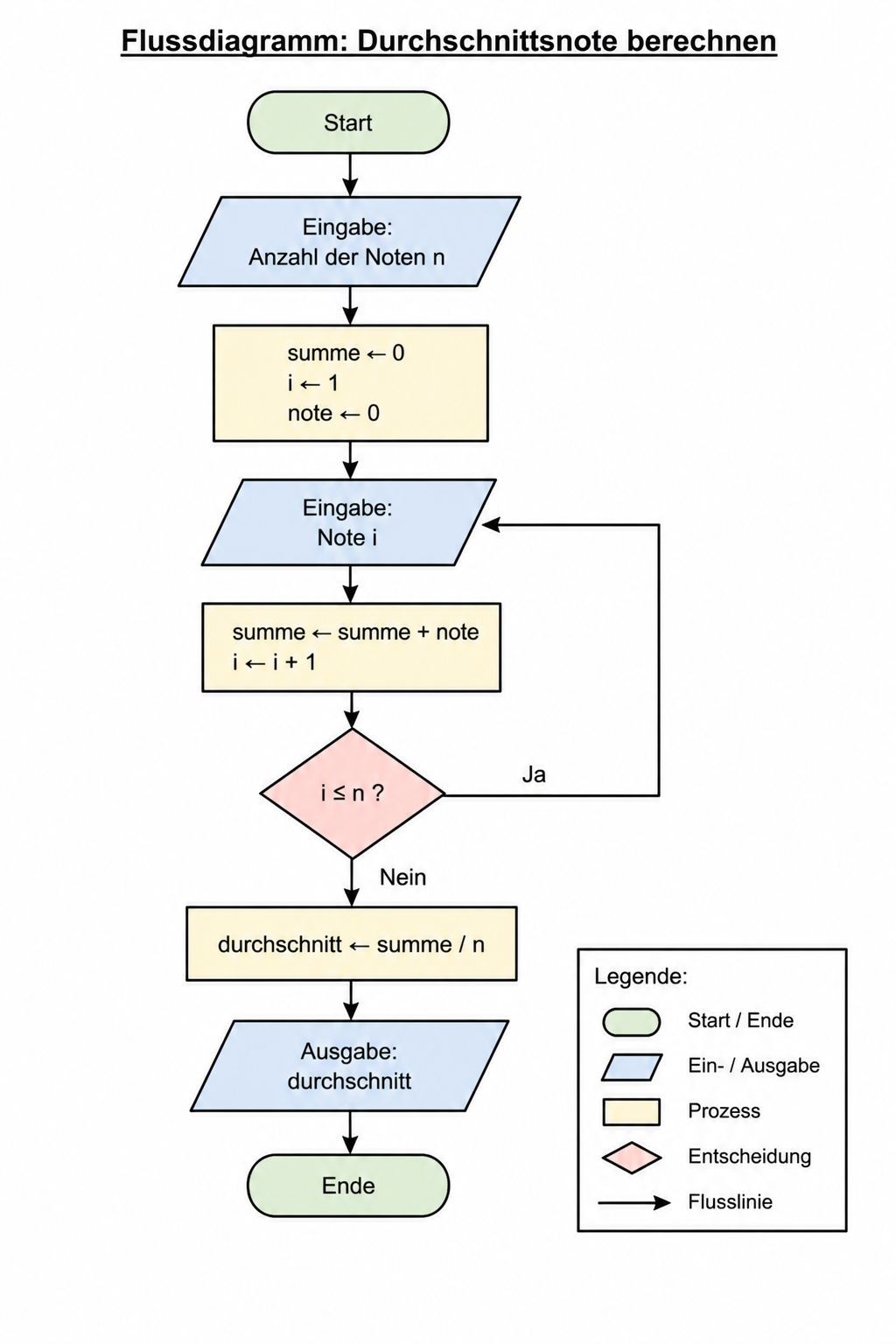
Einsatz: Prozesse und Algorithmen dokumentieren. Breiter Einsatz außerhalb der Informatik (Qualitätsmanagement, Logistik).
Stärke: Weit verbreitet, normiert, werkzeugunterstützt.
Schwäche: Erlaubt Sprünge (goto-Äquivalente), kann unstrukturierte Programme darstellen.